Fan-Out Fan-In Pattern in Go: Parallel Processing Made Simple
You need to fetch data from 10 different APIs. You need to process 1000 files. You need to check 500 URLs. Doing them one by one takes forever. Spinning up separate goroutines for each and trying to collect results turns into spaghetti code with race conditions.
The Fan-Out Fan-In pattern elegantly solves this problem. It's the pattern you reach for when you have one input, need to process it in parallel, and collect all results into a single output.
The Real World Parallel: A Call Center
Think of it like this: Imagine a call center that handles customer complaints. One complaint comes in (single input). The manager fans it out to multiple specialists: one checks the order history, another checks shipping status, another looks at previous complaints. Each works independently and in parallel. Then all their findings fan back into a single report for the customer. This is Fan-Out Fan-In.
Fan-Out: Distribute work to multiple workers running in parallel
Fan-In: Collect results from all workers into a single channel
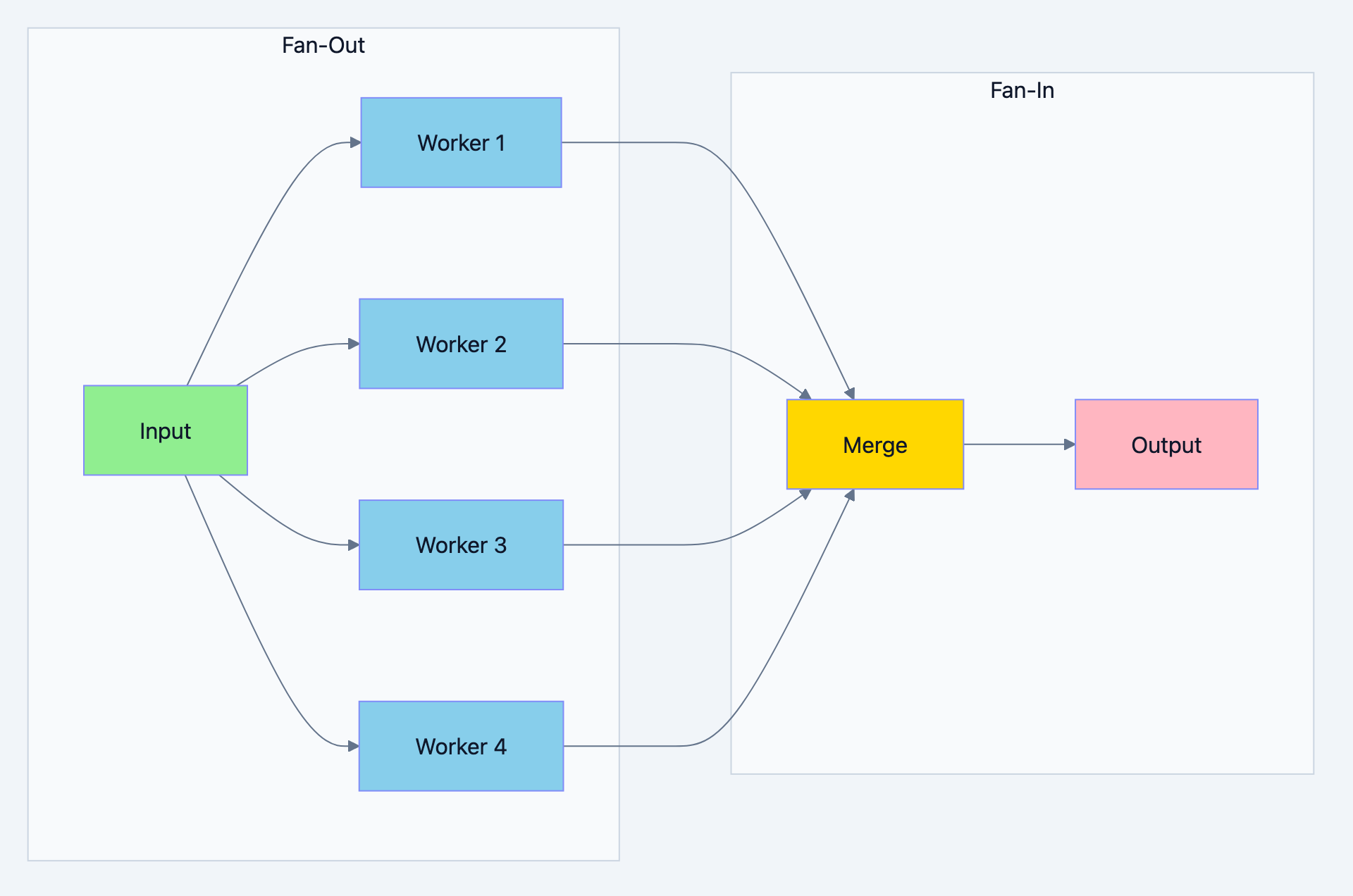
Concurrency pattern diagram 1
Why Fan-Out Fan-In?
Consider fetching prices from multiple vendors:
go// Filename: sequential_vs_parallel.go package main import ( "fmt" "time" ) // Sequential approach - SLOW func getPrice Sequential(vendors []string) []float64 { prices := make([]float64, len(vendors)) for i, vendor := range vendors { // Each call takes 200ms prices[i] = fetchPrice(vendor) } return prices // Total time: 200ms * 10 vendors = 2 seconds } // Fan-Out Fan-In approach - FAST func getPriceParallel(vendors []string) []float64 { // Fan-out: Start all requests in parallel // Fan-in: Collect all results // Total time: ~200ms (all run simultaneously) return nil // Implementation below } func fetchPrice(vendor string) float64 { time.Sleep(200 * time.Millisecond) // Simulate API call return 99.99 } func main() { vendors := make([]string, 10) for i := range vendors { vendors[i] = fmt.Sprintf("vendor-%d", i) } fmt.Println("Sequential approach: 10 vendors × 200ms = 2000ms") fmt.Println("Fan-Out Fan-In: All parallel = ~200ms") fmt.Println("\nSpeedup: 10x faster!") }
Basic Fan-Out Fan-In Implementation
Let's build it step by step:
go// Filename: basic_fan_out_fan_in.go package main import ( "fmt" "math/rand" "sync" "time" ) // Result holds the output of a single worker type Result struct { WorkerID int Value int Duration time.Duration } // fanOut distributes work to multiple workers // Why: Each worker runs in its own goroutine, processing independently func fanOut(input int, numWorkers int) []<-chan Result { // Create a slice to hold all output channels channels := make([]<-chan Result, numWorkers) for i := 0; i < numWorkers; i++ { channels[i] = worker(i, input) } return channels } // worker processes the input and returns results on a channel // Why: Returning a channel allows the caller to receive results asynchronously func worker(id int, input int) <-chan Result { // Why: Each worker has its own output channel out := make(chan Result) go func() { defer close(out) start := time.Now() // Simulate variable processing time processingTime := time.Duration(100+rand.Intn(200)) * time.Millisecond time.Sleep(processingTime) // Do some "work" result := input * (id + 1) out <- Result{ WorkerID: id, Value: result, Duration: time.Since(start), } }() return out } // fanIn merges multiple channels into a single channel // Why: Single output channel is easier to consume than multiple func fanIn(channels []<-chan Result) <-chan Result { // Why: WaitGroup tracks when all input channels are closed var wg sync.WaitGroup merged := make(chan Result) // Start a goroutine for each input channel // Why: Each goroutine forwards values from its channel to the merged channel for _, ch := range channels { wg.Add(1) go func(c <-chan Result) { defer wg.Done() for result := range c { merged <- result } }(ch) } // Close merged channel when all inputs are done // Why: This must be in a separate goroutine to avoid blocking go func() { wg.Wait() close(merged) }() return merged } func main() { rand.Seed(time.Now().UnixNano()) input := 10 numWorkers := 5 fmt.Printf("Input: %d\n", input) fmt.Printf("Workers: %d\n\n", numWorkers) start := time.Now() // Fan-Out: Distribute work to workers workerChannels := fanOut(input, numWorkers) // Fan-In: Merge all results into single channel results := fanIn(workerChannels) // Collect results fmt.Println("Results (in order of completion):") var total int for result := range results { fmt.Printf(" Worker %d: %d (took %v)\n", result.WorkerID, result.Value, result.Duration) total += result.Value } fmt.Printf("\nTotal: %d\n", total) fmt.Printf("Total time: %v\n", time.Since(start)) fmt.Println("\nNotice: All workers ran in parallel!") }
Expected Output:
Input: 10 Workers: 5 Results (in order of completion): Worker 2: 30 (took 112ms) Worker 0: 10 (took 145ms) Worker 4: 50 (took 189ms) Worker 1: 20 (took 234ms) Worker 3: 40 (took 278ms) Total: 150 Total time: 280ms Notice: All workers ran in parallel!
Real World Example 1: Multi-API Price Aggregator
Building a price comparison service that fetches from multiple vendors:
go// Filename: price_aggregator.go package main import ( "context" "encoding/json" "fmt" "math/rand" "sort" "sync" "time" ) // Vendor represents a price source type Vendor struct { Name string BaseURL string Timeout time.Duration } // PriceQuote represents a price from a vendor type PriceQuote struct { VendorName string ProductID string Price float64 Currency string InStock bool FetchTime time.Duration Error error } // PriceAggregator fetches prices from multiple vendors in parallel type PriceAggregator struct { vendors []Vendor timeout time.Duration } // NewPriceAggregator creates a new aggregator func NewPriceAggregator(vendors []Vendor, timeout time.Duration) *PriceAggregator { return &PriceAggregator{ vendors: vendors, timeout: timeout, } } // GetBestPrice fetches prices from all vendors and returns the best one func (pa *PriceAggregator) GetBestPrice(ctx context.Context, productID string) (*PriceQuote, []PriceQuote, error) { ctx, cancel := context.WithTimeout(ctx, pa.timeout) defer cancel() // Fan-Out: Start fetching from all vendors in parallel quoteChannels := make([]<-chan PriceQuote, len(pa.vendors)) for i, vendor := range pa.vendors { quoteChannels[i] = pa.fetchPrice(ctx, vendor, productID) } // Fan-In: Merge all quote channels allQuotes := pa.mergeQuotes(quoteChannels) // Collect all quotes var quotes []PriceQuote for quote := range allQuotes { quotes = append(quotes, quote) } // Find best price (lowest price, in stock) var bestQuote *PriceQuote for i := range quotes { quote := "es[i] if quote.Error != nil || !quote.InStock { continue } if bestQuote == nil || quote.Price < bestQuote.Price { bestQuote = quote } } return bestQuote, quotes, nil } // fetchPrice fetches price from a single vendor func (pa *PriceAggregator) fetchPrice(ctx context.Context, vendor Vendor, productID string) <-chan PriceQuote { out := make(chan PriceQuote, 1) go func() { defer close(out) start := time.Now() // Simulate API call with variable latency latency := time.Duration(50+rand.Intn(200)) * time.Millisecond select { case <-ctx.Done(): out <- PriceQuote{ VendorName: vendor.Name, ProductID: productID, Error: ctx.Err(), FetchTime: time.Since(start), } return case <-time.After(latency): // Simulate response } // Simulate random price and stock status price := 50.0 + rand.Float64()*100.0 inStock := rand.Float32() > 0.2 // 80% in stock // Simulate occasional failures (10% chance) var err error if rand.Float32() < 0.1 { err = fmt.Errorf("connection timeout") } out <- PriceQuote{ VendorName: vendor.Name, ProductID: productID, Price: price, Currency: "USD", InStock: inStock, FetchTime: time.Since(start), Error: err, } }() return out } // mergeQuotes merges multiple quote channels into one func (pa *PriceAggregator) mergeQuotes(channels []<-chan PriceQuote) <-chan PriceQuote { var wg sync.WaitGroup merged := make(chan PriceQuote) for _, ch := range channels { wg.Add(1) go func(c <-chan PriceQuote) { defer wg.Done() for quote := range c { merged <- quote } }(ch) } go func() { wg.Wait() close(merged) }() return merged } func main() { rand.Seed(time.Now().UnixNano()) // Define vendors vendors := []Vendor{ {Name: "Amazon", BaseURL: "https://api.amazon.com", Timeout: 500 * time.Millisecond}, {Name: "BestBuy", BaseURL: "https://api.bestbuy.com", Timeout: 500 * time.Millisecond}, {Name: "Walmart", BaseURL: "https://api.walmart.com", Timeout: 500 * time.Millisecond}, {Name: "Target", BaseURL: "https://api.target.com", Timeout: 500 * time.Millisecond}, {Name: "Newegg", BaseURL: "https://api.newegg.com", Timeout: 500 * time.Millisecond}, {Name: "BHPhoto", BaseURL: "https://api.bhphoto.com", Timeout: 500 * time.Millisecond}, } aggregator := NewPriceAggregator(vendors, 1*time.Second) productID := "LAPTOP-XPS-15" fmt.Printf("Searching for best price on: %s\n", productID) fmt.Printf("Checking %d vendors in parallel...\n\n", len(vendors)) start := time.Now() bestQuote, allQuotes, err := aggregator.GetBestPrice(context.Background(), productID) totalTime := time.Since(start) if err != nil { fmt.Printf("Error: %v\n", err) return } // Sort quotes by price for display sort.Slice(allQuotes, func(i, j int) bool { if allQuotes[i].Error != nil { return false } if allQuotes[j].Error != nil { return true } return allQuotes[i].Price < allQuotes[j].Price }) // Display all quotes fmt.Println("All Quotes:") fmt.Println("+------------+----------+----------+------------+") fmt.Println("| Vendor | Price | In Stock | Fetch Time |") fmt.Println("+------------+----------+----------+------------+") for _, quote := range allQuotes { if quote.Error != nil { fmt.Printf("| %-10s | ERROR | - | %-10v |\n", quote.VendorName, quote.FetchTime.Round(time.Millisecond)) } else { stock := "Yes" if !quote.InStock { stock = "No" } fmt.Printf("| %-10s | $%-7.2f | %-8s | %-10v |\n", quote.VendorName, quote.Price, stock, quote.FetchTime.Round(time.Millisecond)) } } fmt.Println("+------------+----------+----------+------------+") fmt.Printf("\nTotal fetch time: %v (all vendors queried in parallel)\n", totalTime.Round(time.Millisecond)) if bestQuote != nil { fmt.Printf("\n🏆 Best Deal: %s at $%.2f\n", bestQuote.VendorName, bestQuote.Price) } else { fmt.Println("\n❌ No vendors have this item in stock") } }
Expected Output:
Searching for best price on: LAPTOP-XPS-15 Checking 6 vendors in parallel... All Quotes: +------------+----------+----------+------------+ | Vendor | Price | In Stock | Fetch Time | +------------+----------+----------+------------+ | BestBuy | $62.45 | Yes | 89ms | | Walmart | $78.23 | Yes | 156ms | | Amazon | $94.12 | Yes | 123ms | | Target | $101.56 | No | 178ms | | BHPhoto | $112.89 | Yes | 201ms | | Newegg | ERROR | - | 95ms | +------------+----------+----------+------------+ Total fetch time: 203ms (all vendors queried in parallel) 🏆 Best Deal: BestBuy at $62.45
Real World Example 2: Parallel File Processor
Processing multiple files in parallel and aggregating results:
go// Filename: parallel_file_processor.go package main import ( "context" "crypto/md5" "fmt" "math/rand" "path/filepath" "sync" "time" ) // FileInfo represents metadata about a file type FileInfo struct { Path string Size int64 Hash string WordCount int LineCount int } // ProcessResult represents the result of processing a file type ProcessResult struct { File FileInfo Duration time.Duration Error error } // FileProcessor processes files in parallel using Fan-Out Fan-In type FileProcessor struct { maxWorkers int } // NewFileProcessor creates a new processor func NewFileProcessor(maxWorkers int) *FileProcessor { return &FileProcessor{maxWorkers: maxWorkers} } // ProcessFiles processes multiple files in parallel func (fp *FileProcessor) ProcessFiles(ctx context.Context, paths []string) ([]ProcessResult, error) { // Create job channel jobs := make(chan string, len(paths)) // Fan-Out: Create workers resultChannels := make([]<-chan ProcessResult, fp.maxWorkers) for i := 0; i < fp.maxWorkers; i++ { resultChannels[i] = fp.worker(ctx, i, jobs) } // Send jobs go func() { for _, path := range paths { jobs <- path } close(jobs) }() // Fan-In: Merge results merged := fp.mergeResults(resultChannels) // Collect all results var results []ProcessResult for result := range merged { results = append(results, result) } return results, nil } // worker processes files from the job channel func (fp *FileProcessor) worker(ctx context.Context, id int, jobs <-chan string) <-chan ProcessResult { out := make(chan ProcessResult) go func() { defer close(out) for path := range jobs { select { case <-ctx.Done(): out <- ProcessResult{ File: FileInfo{Path: path}, Error: ctx.Err(), } return default: result := fp.processFile(path) out <- result } } }() return out } // processFile simulates processing a single file func (fp *FileProcessor) processFile(path string) ProcessResult { start := time.Now() // Simulate variable processing time based on "file size" processingTime := time.Duration(50+rand.Intn(150)) * time.Millisecond time.Sleep(processingTime) // Simulate file analysis size := int64(1000 + rand.Intn(100000)) hash := fmt.Sprintf("%x", md5.Sum([]byte(path)))[:8] wordCount := rand.Intn(5000) + 100 lineCount := rand.Intn(500) + 10 // Simulate occasional errors (5% chance) var err error if rand.Float32() < 0.05 { err = fmt.Errorf("permission denied") } return ProcessResult{ File: FileInfo{ Path: path, Size: size, Hash: hash, WordCount: wordCount, LineCount: lineCount, }, Duration: time.Since(start), Error: err, } } // mergeResults merges multiple result channels func (fp *FileProcessor) mergeResults(channels []<-chan ProcessResult) <-chan ProcessResult { var wg sync.WaitGroup merged := make(chan ProcessResult) for _, ch := range channels { wg.Add(1) go func(c <-chan ProcessResult) { defer wg.Done() for result := range c { merged <- result } }(ch) } go func() { wg.Wait() close(merged) }() return merged } // Summary holds aggregate statistics type Summary struct { TotalFiles int SuccessCount int ErrorCount int TotalBytes int64 TotalWords int TotalLines int TotalDuration time.Duration AvgDuration time.Duration } func main() { rand.Seed(time.Now().UnixNano()) // Generate test files files := make([]string, 20) for i := range files { files[i] = filepath.Join("/data/documents", fmt.Sprintf("file_%03d.txt", i+1)) } processor := NewFileProcessor(5) fmt.Printf("Processing %d files with %d parallel workers...\n\n", len(files), 5) start := time.Now() results, err := processor.ProcessFiles(context.Background(), files) totalTime := time.Since(start) if err != nil { fmt.Printf("Error: %v\n", err) return } // Calculate summary summary := Summary{TotalFiles: len(results)} for _, r := range results { if r.Error != nil { summary.ErrorCount++ } else { summary.SuccessCount++ summary.TotalBytes += r.File.Size summary.TotalWords += r.File.WordCount summary.TotalLines += r.File.LineCount } summary.TotalDuration += r.Duration } summary.AvgDuration = summary.TotalDuration / time.Duration(len(results)) // Display results fmt.Println("Processing Results:") fmt.Println("+" + "-"*60 + "+") for _, r := range results { if r.Error != nil { fmt.Printf("| ❌ %-40s | ERROR: %v\n", filepath.Base(r.File.Path), r.Error) } else { fmt.Printf("| ✅ %-40s | %6d bytes | %4d lines | %v\n", filepath.Base(r.File.Path), r.File.Size, r.File.LineCount, r.Duration.Round(time.Millisecond)) } } fmt.Println("+" + "-"*60 + "+") fmt.Println("\n📊 Summary:") fmt.Printf(" Files processed: %d (%d success, %d failed)\n", summary.TotalFiles, summary.SuccessCount, summary.ErrorCount) fmt.Printf(" Total bytes: %d KB\n", summary.TotalBytes/1024) fmt.Printf(" Total words: %d\n", summary.TotalWords) fmt.Printf(" Total lines: %d\n", summary.TotalLines) fmt.Printf(" Avg processing time per file: %v\n", summary.AvgDuration.Round(time.Millisecond)) fmt.Printf(" Total wall-clock time: %v\n", totalTime.Round(time.Millisecond)) // Calculate speedup sequentialTime := summary.TotalDuration speedup := float64(sequentialTime) / float64(totalTime) fmt.Printf("\n⚡ Speedup: %.1fx faster than sequential processing\n", speedup) }
Expected Output:
Processing 20 files with 5 parallel workers... Processing Results: +------------------------------------------------------------+ | ✅ file_001.txt | 45623 bytes | 234 lines | 87ms | ✅ file_002.txt | 12456 bytes | 156 lines | 123ms | ✅ file_003.txt | 78234 bytes | 445 lines | 156ms | ❌ file_004.txt | ERROR: permission denied | ✅ file_005.txt | 34521 bytes | 289 lines | 98ms ... +------------------------------------------------------------+ 📊 Summary: Files processed: 20 (19 success, 1 failed) Total bytes: 892 KB Total words: 48234 Total lines: 5678 Avg processing time per file: 112ms Total wall-clock time: 456ms ⚡ Speedup: 4.9x faster than sequential processing
Real World Example 3: Web Scraper with Fan-Out Fan-In
go// Filename: web_scraper.go package main import ( "context" "fmt" "math/rand" "sync" "time" ) // Page represents a scraped web page type Page struct { URL string Title string WordCount int Links []string StatusCode int LoadTime time.Duration } // ScrapeResult represents the result of scraping a URL type ScrapeResult struct { Page Page Error error } // WebScraper scrapes multiple URLs in parallel type WebScraper struct { maxConcurrency int timeout time.Duration rateLimit time.Duration } // NewWebScraper creates a new scraper func NewWebScraper(maxConcurrency int, timeout time.Duration) *WebScraper { return &WebScraper{ maxConcurrency: maxConcurrency, timeout: timeout, rateLimit: 100 * time.Millisecond, // Politeness delay } } // ScrapeAll scrapes multiple URLs using Fan-Out Fan-In func (ws *WebScraper) ScrapeAll(ctx context.Context, urls []string) []ScrapeResult { ctx, cancel := context.WithTimeout(ctx, ws.timeout) defer cancel() // Create URL channel urlChan := make(chan string, len(urls)) // Fan-Out: Create scraper workers resultChannels := make([]<-chan ScrapeResult, ws.maxConcurrency) for i := 0; i < ws.maxConcurrency; i++ { resultChannels[i] = ws.scrapeWorker(ctx, i, urlChan) } // Feed URLs go func() { for _, url := range urls { urlChan <- url } close(urlChan) }() // Fan-In: Merge all results merged := ws.mergeResults(resultChannels) // Collect results var results []ScrapeResult for result := range merged { results = append(results, result) } return results } // scrapeWorker is a worker that scrapes URLs from the channel func (ws *WebScraper) scrapeWorker(ctx context.Context, id int, urls <-chan string) <-chan ScrapeResult { out := make(chan ScrapeResult) go func() { defer close(out) for url := range urls { select { case <-ctx.Done(): out <- ScrapeResult{ Page: Page{URL: url}, Error: ctx.Err(), } return default: // Rate limiting - be polite to servers time.Sleep(ws.rateLimit) result := ws.scrapePage(url) out <- result } } }() return out } // scrapePage simulates scraping a single page func (ws *WebScraper) scrapePage(url string) ScrapeResult { start := time.Now() // Simulate network latency latency := time.Duration(100+rand.Intn(300)) * time.Millisecond time.Sleep(latency) // Simulate different responses statusCode := 200 if rand.Float32() < 0.1 { statusCode = 404 } else if rand.Float32() < 0.05 { statusCode = 500 } if statusCode != 200 { return ScrapeResult{ Page: Page{ URL: url, StatusCode: statusCode, LoadTime: time.Since(start), }, Error: fmt.Errorf("HTTP %d", statusCode), } } // Simulate successful scrape return ScrapeResult{ Page: Page{ URL: url, Title: fmt.Sprintf("Page: %s", url), WordCount: rand.Intn(2000) + 100, Links: generateLinks(rand.Intn(10) + 1), StatusCode: 200, LoadTime: time.Since(start), }, } } func generateLinks(count int) []string { links := make([]string, count) for i := range links { links[i] = fmt.Sprintf("https://example.com/page-%d", rand.Intn(1000)) } return links } // mergeResults merges multiple result channels func (ws *WebScraper) mergeResults(channels []<-chan ScrapeResult) <-chan ScrapeResult { var wg sync.WaitGroup merged := make(chan ScrapeResult) for _, ch := range channels { wg.Add(1) go func(c <-chan ScrapeResult) { defer wg.Done() for result := range c { merged <- result } }(ch) } go func() { wg.Wait() close(merged) }() return merged } func main() { rand.Seed(time.Now().UnixNano()) // URLs to scrape urls := []string{ "https://example.com/", "https://example.com/about", "https://example.com/products", "https://example.com/blog", "https://example.com/contact", "https://example.com/faq", "https://example.com/terms", "https://example.com/privacy", "https://example.com/careers", "https://example.com/support", "https://example.com/pricing", "https://example.com/features", } scraper := NewWebScraper(4, 30*time.Second) fmt.Printf("🕷️ Web Scraper - Fan-Out Fan-In Pattern\n") fmt.Printf(" URLs to scrape: %d\n", len(urls)) fmt.Printf(" Concurrent workers: %d\n\n", 4) start := time.Now() results := scraper.ScrapeAll(context.Background(), urls) totalTime := time.Since(start) // Display results fmt.Println("Results:") fmt.Println("+" + "-"*70 + "+") successCount := 0 totalWords := 0 totalLinks := 0 var totalLoadTime time.Duration for _, r := range results { if r.Error != nil { fmt.Printf("| ❌ %-50s | %v\n", r.Page.URL, r.Error) } else { fmt.Printf("| ✅ %-50s | %4d words | %2d links | %v\n", r.Page.URL, r.Page.WordCount, len(r.Page.Links), r.Page.LoadTime.Round(time.Millisecond)) successCount++ totalWords += r.Page.WordCount totalLinks += len(r.Page.Links) } totalLoadTime += r.Page.LoadTime } fmt.Println("+" + "-"*70 + "+") fmt.Println("\n📊 Statistics:") fmt.Printf(" Pages scraped: %d/%d successful\n", successCount, len(urls)) fmt.Printf(" Total words: %d\n", totalWords) fmt.Printf(" Total links found: %d\n", totalLinks) fmt.Printf(" Sum of load times: %v\n", totalLoadTime.Round(time.Millisecond)) fmt.Printf(" Actual wall-clock time: %v\n", totalTime.Round(time.Millisecond)) fmt.Printf(" Efficiency: %.1fx speedup from parallelization\n", float64(totalLoadTime)/float64(totalTime)) }
Advanced: Fan-Out Fan-In with Bounded Concurrency
Sometimes you want Fan-Out Fan-In but with a limit on concurrent operations:
go// Filename: bounded_fan_out.go package main import ( "context" "fmt" "sync" "time" ) // BoundedFanOut limits the number of concurrent operations // Why: Useful when you have many items but limited resources func BoundedFanOut(ctx context.Context, items []int, maxConcurrency int, process func(int) int) []int { // Semaphore channel to limit concurrency semaphore := make(chan struct{}, maxConcurrency) // Results with mutex for safe concurrent writes results := make([]int, len(items)) var wg sync.WaitGroup for i, item := range items { wg.Add(1) go func(index int, value int) { defer wg.Done() // Acquire semaphore (blocks if maxConcurrency reached) select { case semaphore <- struct{}{}: defer func() { <-semaphore }() // Release on exit case <-ctx.Done(): return } // Process item results[index] = process(value) }(i, item) } wg.Wait() return results } // Alternative: Using errgroup for better error handling func BoundedFanOutWithErrgroup(ctx context.Context, items []int, maxConcurrency int, process func(int) (int, error)) ([]int, error) { results := make([]int, len(items)) semaphore := make(chan struct{}, maxConcurrency) var wg sync.WaitGroup var firstErr error var errOnce sync.Once for i, item := range items { wg.Add(1) go func(index int, value int) { defer wg.Done() // Acquire semaphore semaphore <- struct{}{} defer func() { <-semaphore }() result, err := process(value) if err != nil { errOnce.Do(func() { firstErr = err }) return } results[index] = result }(i, item) } wg.Wait() return results, firstErr } func main() { items := make([]int, 20) for i := range items { items[i] = i + 1 } fmt.Println("Bounded Fan-Out (max 3 concurrent):") fmt.Println("=" + "=") start := time.Now() activeCount := 0 maxActive := 0 var mu sync.Mutex results := BoundedFanOut(context.Background(), items, 3, func(n int) int { mu.Lock() activeCount++ if activeCount > maxActive { maxActive = activeCount } current := activeCount mu.Unlock() fmt.Printf("Processing %d (active: %d)\n", n, current) time.Sleep(100 * time.Millisecond) mu.Lock() activeCount-- mu.Unlock() return n * n }) fmt.Printf("\nResults: %v\n", results) fmt.Printf("Max concurrent: %d\n", maxActive) fmt.Printf("Total time: %v\n", time.Since(start).Round(time.Millisecond)) }
Fan-Out Fan-In with First-Response-Wins
Sometimes you only need the first successful response:
go// Filename: first_response_wins.go package main import ( "context" "fmt" "math/rand" "time" ) // Query represents a query to multiple sources type Query struct { Term string } // SearchResult represents a search result type SearchResult struct { Source string Data string Took time.Duration } // SearchFirstResult queries multiple sources and returns the first successful response // Why: Useful for redundant services where any response is acceptable func SearchFirstResult(ctx context.Context, query Query, sources []string) (*SearchResult, error) { ctx, cancel := context.WithCancel(ctx) defer cancel() // Cancel all other searches once we have a result // Create result channel results := make(chan SearchResult, len(sources)) errors := make(chan error, len(sources)) // Fan-Out: Query all sources in parallel for _, source := range sources { go func(src string) { result, err := searchSource(ctx, src, query) if err != nil { errors <- err return } results <- result }(source) } // Wait for first result or all errors var errCount int for { select { case result := <-results: return &result, nil // First response wins! case <-errors: errCount++ if errCount == len(sources) { return nil, fmt.Errorf("all sources failed") } case <-ctx.Done(): return nil, ctx.Err() } } } // searchSource simulates searching a single source func searchSource(ctx context.Context, source string, query Query) (SearchResult, error) { // Simulate variable response time responseTime := time.Duration(100+rand.Intn(400)) * time.Millisecond select { case <-time.After(responseTime): // Simulate 20% failure rate if rand.Float32() < 0.2 { return SearchResult{}, fmt.Errorf("%s: connection refused", source) } return SearchResult{ Source: source, Data: fmt.Sprintf("Results from %s for '%s'", source, query.Term), Took: responseTime, }, nil case <-ctx.Done(): return SearchResult{}, ctx.Err() } } func main() { rand.Seed(time.Now().UnixNano()) sources := []string{ "Google", "Bing", "DuckDuckGo", "Yahoo", "Yandex", } query := Query{Term: "golang concurrency"} fmt.Printf("Searching for: %s\n", query.Term) fmt.Printf("Sources: %v\n\n", sources) start := time.Now() result, err := SearchFirstResult(context.Background(), query, sources) if err != nil { fmt.Printf("Error: %v\n", err) return } fmt.Printf("🏆 First response from: %s\n", result.Source) fmt.Printf(" Response time: %v\n", result.Took.Round(time.Millisecond)) fmt.Printf(" Data: %s\n", result.Data) fmt.Printf("\n Total wall-clock time: %v\n", time.Since(start).Round(time.Millisecond)) fmt.Println("\n (Other searches were cancelled after first response)") }
When to Use Fan-Out Fan-In
Perfect Use Cases
| Scenario | Why Fan-Out Fan-In Fits |
|---|---|
| Multi-API aggregation | Query all APIs in parallel, combine results |
| Parallel file processing | Process files concurrently, aggregate stats |
| Distributed search | Search multiple indexes, merge results |
| Price comparison | Fetch from all vendors, find best |
| Health checks | Check all services simultaneously |
| Data validation | Validate against multiple rules in parallel |
| Map operations | Apply function to all items in parallel |
When to Choose Something Else
| Scenario | Better Pattern |
|---|---|
| Sequential dependencies | Pipeline pattern |
| Limited resources | Worker Pool pattern |
| Stream processing | Pipeline with stages |
| Single consumer | Simple goroutine |
| Order matters | Sequential or ordered pipeline |
Summary
Fan-Out Fan-In is your go-to pattern when you need to:
- Execute multiple independent operations in parallel
- Aggregate results from multiple sources
- Reduce latency by parallelizing I/O-bound operations
Key Takeaways:
- Fan-Out: Distribute work to multiple goroutines running in parallel
- Fan-In: Merge results from all goroutines into a single channel
- Use context: For timeout and cancellation across all workers
- Buffer appropriately: Prevent goroutine blocking
- Consider bounded concurrency: When resources are limited
Next Steps
- Practice: Build a multi-source news aggregator
- Explore: Pipeline pattern for sequential processing stages
- Read: Go's context package for deadline propagation
- Build: Add metrics to track fan-out efficiency