Worker Pool Pattern in Go: Managing Concurrent Tasks Like a Factory Floor
You have 10,000 images to resize. You have 50,000 emails to send. You have a million records to process. Your first instinct might be to spin up a goroutine for each task. After all, goroutines are cheap, right?
Then reality hits. Your database crashes because you opened 10,000 connections simultaneously. Your API provider blocks you for exceeding rate limits. Your server runs out of memory. Your program becomes a chaotic mess where nothing completes because everything is fighting for resources.
This is where the Worker Pool pattern saves the day. It's the difference between a chaotic mob and a well-organized assembly line.
The Real World Parallel: A Restaurant Kitchen
Think of it like this: Imagine a busy restaurant on a Saturday night. Orders are flooding in. The kitchen has 5 chefs. Now, the restaurant could hire 100 chefs for the rush hour, but that would be expensive, chaotic, and they'd bump into each other constantly. Instead, the 5 chefs work from a queue of orders. When one chef finishes a dish, they take the next order from the queue. The kitchen stays organized, dishes come out consistently, and resources are used efficiently.
This is exactly what a Worker Pool does for your Go program:
- Fixed number of workers (goroutines) instead of unlimited
- Queue of jobs waiting to be processed
- Controlled resource usage (database connections, memory, API calls)
- Predictable performance under load
Why You Need Worker Pools
Let's see what happens without one:
go// Filename: bad_approach.go // DON'T DO THIS - This creates 10,000 goroutines and database connections! package main import ( "database/sql" "fmt" "sync" ) func processWithoutPool(userIDs []int, db *sql.DB) { var wg sync.WaitGroup for _, userID := range userIDs { wg.Add(1) go func(id int) { defer wg.Done() // Each goroutine opens a new database connection // With 10,000 users, you'll have 10,000 concurrent connections! row := db.QueryRow("SELECT * FROM users WHERE id = ?", id) // Process row... _ = row }(userID) } wg.Wait() } func main() { // With 10,000 users, this will: // 1. Exhaust database connection pool // 2. Overwhelm the database server // 3. Cause connection timeouts and errors // 4. Potentially crash your application userIDs := make([]int, 10000) for i := range userIDs { userIDs[i] = i + 1 } // db := connectToDatabase() // processWithoutPool(userIDs, db) fmt.Println("This approach would cause chaos with 10,000 concurrent operations!") }
Expected Output:
This approach would cause chaos with 10,000 concurrent operations!
The Problems:
- Resource exhaustion: Databases have connection limits (often 100-500)
- Memory pressure: 10,000 goroutines with their stacks eat memory
- Thundering herd: All goroutines compete for the same resources simultaneously
- No backpressure: System accepts work faster than it can process
- Unpredictable latency: Everything slows down under contention
The Worker Pool Solution
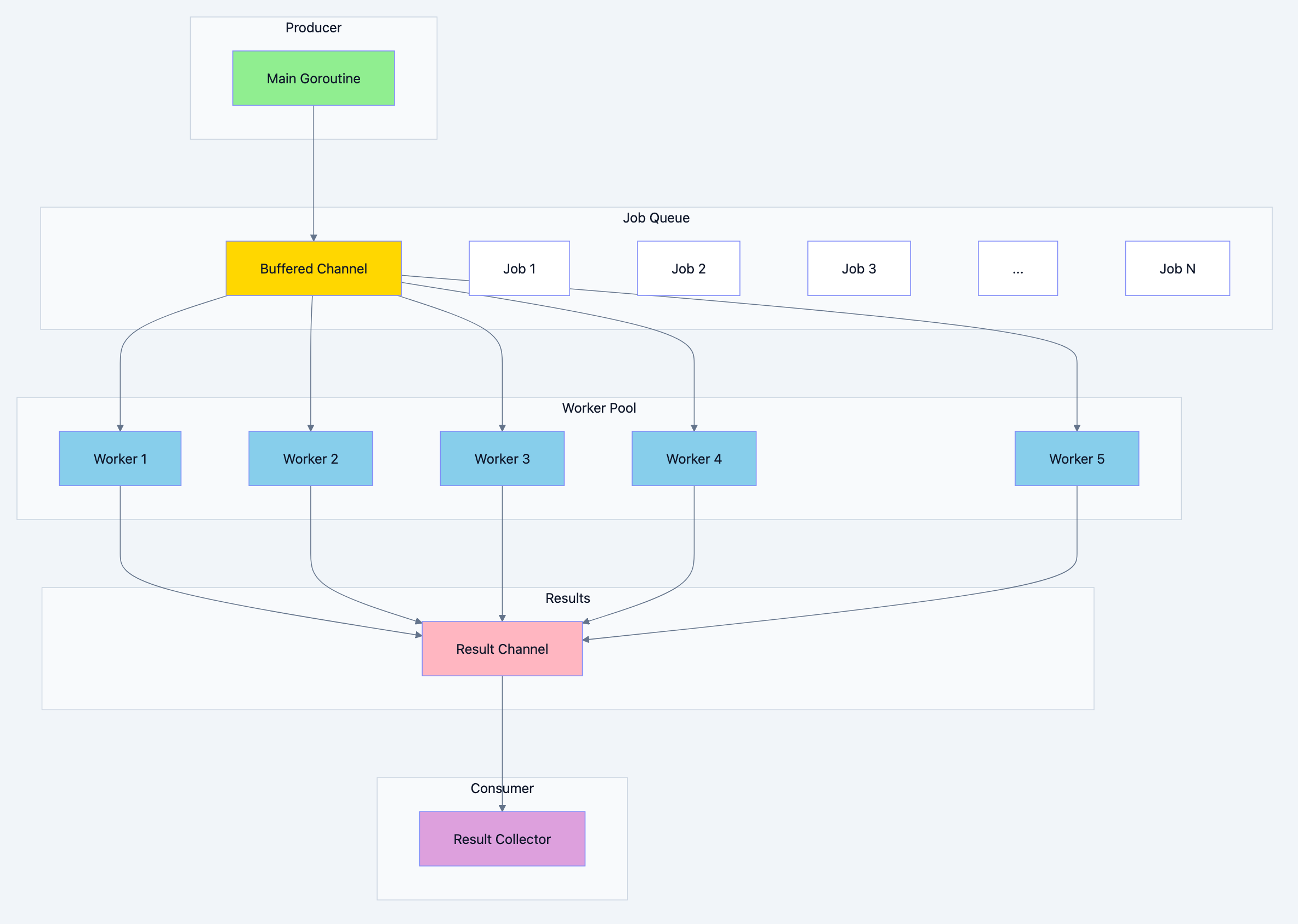
Concurrency pattern diagram 1
Basic Worker Pool Implementation
Let's build a worker pool step by step:
go// Filename: basic_worker_pool.go package main import ( "fmt" "sync" "time" ) // Job represents a unit of work to be done // Why: Encapsulating work in a struct makes it easy to pass around // and allows for adding metadata like priority or retry count later type Job struct { ID int Data string } // Result represents the outcome of processing a job // Why: Separating Job and Result allows workers to return // different data structures than what they receive type Result struct { JobID int Output string Duration time.Duration Error error } // worker is a goroutine that processes jobs from the jobs channel // Why: Each worker runs in its own goroutine, taking jobs from // a shared channel. This creates natural load balancing - faster // workers naturally take more jobs. func worker(id int, jobs <-chan Job, results chan<- Result, wg *sync.WaitGroup) { // Why: defer ensures Done() is called even if worker panics defer wg.Done() // Why: range over channel automatically exits when channel closes for job := range jobs { start := time.Now() // Simulate some work (in real code, this would be actual processing) time.Sleep(time.Duration(50+job.ID%100) * time.Millisecond) // Process the job output := fmt.Sprintf("Worker %d processed job %d: %s", id, job.ID, job.Data) // Send result back results <- Result{ JobID: job.ID, Output: output, Duration: time.Since(start), } } fmt.Printf("Worker %d: shutting down\n", id) } func main() { const numWorkers = 5 const numJobs = 20 // Why: Buffered channels prevent blocking when sending jobs // Buffer size equals number of jobs so producer doesn't block jobs := make(chan Job, numJobs) results := make(chan Result, numJobs) var wg sync.WaitGroup // Start workers // Why: Starting workers before sending jobs ensures no jobs are missed fmt.Printf("Starting %d workers...\n", numWorkers) for w := 1; w <= numWorkers; w++ { wg.Add(1) go worker(w, jobs, results, &wg) } // Send jobs // Why: Jobs are sent to a channel, not directly to workers // This decouples job creation from job processing fmt.Printf("Sending %d jobs...\n", numJobs) for j := 1; j <= numJobs; j++ { jobs <- Job{ ID: j, Data: fmt.Sprintf("task-%d", j), } } close(jobs) // Signal no more jobs are coming // Wait for all workers to finish in a separate goroutine // Why: This allows us to collect results while workers are still running go func() { wg.Wait() close(results) // Safe to close after all workers are done }() // Collect results // Why: Collecting results as they come in (streaming) is more // memory efficient than waiting for all results fmt.Println("\nResults:") for result := range results { fmt.Printf(" Job %d completed in %v\n", result.JobID, result.Duration) } fmt.Println("\nAll jobs completed!") }
Expected Output:
Starting 5 workers... Sending 20 jobs... Results: Job 1 completed in 51ms Job 2 completed in 52ms Job 5 completed in 55ms Job 3 completed in 53ms Job 4 completed in 54ms Job 6 completed in 56ms ... Worker 1: shutting down Worker 3: shutting down Worker 2: shutting down Worker 4: shutting down Worker 5: shutting down All jobs completed!
Real World Example 1: Image Processing Service
Let's build a realistic image processing service that resizes uploaded images:
go// Filename: image_processor.go package main import ( "context" "fmt" "sync" "time" ) // ImageJob represents an image to be processed type ImageJob struct { ImageID string SourceURL string Width int Height int Quality int } // ImageResult represents the processed image type ImageResult struct { ImageID string OutputURL string OriginalSize int64 NewSize int64 Duration time.Duration Error error } // ImageProcessor manages a pool of workers for image processing // Why: Encapsulating the worker pool in a struct makes it reusable // and allows for configuration and lifecycle management type ImageProcessor struct { numWorkers int jobs chan ImageJob results chan ImageResult wg sync.WaitGroup ctx context.Context cancel context.CancelFunc } // NewImageProcessor creates a new image processing pool // Why: Constructor pattern ensures proper initialization func NewImageProcessor(numWorkers, bufferSize int) *ImageProcessor { ctx, cancel := context.WithCancel(context.Background()) return &ImageProcessor{ numWorkers: numWorkers, jobs: make(chan ImageJob, bufferSize), results: make(chan ImageResult, bufferSize), ctx: ctx, cancel: cancel, } } // Start begins the worker pool // Why: Separating Start from New allows for configuration changes // between creation and starting func (p *ImageProcessor) Start() { for i := 1; i <= p.numWorkers; i++ { p.wg.Add(1) go p.worker(i) } fmt.Printf("Image processor started with %d workers\n", p.numWorkers) } // worker processes images from the job queue func (p *ImageProcessor) worker(id int) { defer p.wg.Done() for { select { case <-p.ctx.Done(): // Context cancelled, shut down gracefully fmt.Printf("Worker %d: received shutdown signal\n", id) return case job, ok := <-p.jobs: if !ok { // Channel closed, no more jobs fmt.Printf("Worker %d: job channel closed\n", id) return } result := p.processImage(id, job) p.results <- result } } } // processImage does the actual image processing // Why: Separating processing logic makes it easy to test and modify func (p *ImageProcessor) processImage(workerID int, job ImageJob) ImageResult { start := time.Now() // Simulate image processing steps // In real code, this would use an image library like imaging or bimg // Step 1: Download image (simulated) time.Sleep(50 * time.Millisecond) // Step 2: Decode image (simulated) time.Sleep(30 * time.Millisecond) // Step 3: Resize image (simulated) time.Sleep(100 * time.Millisecond) // Step 4: Encode and save (simulated) time.Sleep(40 * time.Millisecond) // Simulate occasional errors (10% chance) var err error if job.Width > 4000 { err = fmt.Errorf("image too large: max width is 4000px") } return ImageResult{ ImageID: job.ImageID, OutputURL: fmt.Sprintf("https://cdn.example.com/processed/%s_%dx%d.jpg", job.ImageID, job.Width, job.Height), OriginalSize: 2500000, // 2.5 MB simulated NewSize: int64(job.Width * job.Height * 3 / 10), // Rough estimate Duration: time.Since(start), Error: err, } } // Submit adds a job to the processing queue // Why: Method returns immediately, job is processed asynchronously func (p *ImageProcessor) Submit(job ImageJob) { p.jobs <- job } // Results returns the results channel for consuming processed images // Why: Exposing channel allows for flexible result handling func (p *ImageProcessor) Results() <-chan ImageResult { return p.results } // Shutdown gracefully stops the worker pool // Why: Graceful shutdown ensures all in-flight jobs complete func (p *ImageProcessor) Shutdown() { fmt.Println("Initiating graceful shutdown...") // Stop accepting new jobs close(p.jobs) // Wait for workers to finish current jobs p.wg.Wait() // Close results channel close(p.results) fmt.Println("Shutdown complete") } // ForceShutdown immediately stops all workers // Why: Sometimes you need to stop immediately (e.g., critical error) func (p *ImageProcessor) ForceShutdown() { fmt.Println("Force shutdown initiated...") p.cancel() p.wg.Wait() close(p.results) fmt.Println("Force shutdown complete") } func main() { // Create processor with 3 workers and buffer for 100 jobs processor := NewImageProcessor(3, 100) processor.Start() // Start result collector in separate goroutine var resultWg sync.WaitGroup resultWg.Add(1) go func() { defer resultWg.Done() successCount := 0 errorCount := 0 for result := range processor.Results() { if result.Error != nil { errorCount++ fmt.Printf("FAILED: Image %s - %v\n", result.ImageID, result.Error) } else { successCount++ fmt.Printf("SUCCESS: Image %s processed in %v (%.1f KB -> %.1f KB)\n", result.ImageID, result.Duration, float64(result.OriginalSize)/1024, float64(result.NewSize)/1024, ) } } fmt.Printf("\nProcessing complete: %d succeeded, %d failed\n", successCount, errorCount) }() // Submit jobs images := []ImageJob{ {ImageID: "img001", SourceURL: "https://example.com/photo1.jpg", Width: 800, Height: 600, Quality: 85}, {ImageID: "img002", SourceURL: "https://example.com/photo2.jpg", Width: 1200, Height: 800, Quality: 90}, {ImageID: "img003", SourceURL: "https://example.com/photo3.jpg", Width: 1920, Height: 1080, Quality: 95}, {ImageID: "img004", SourceURL: "https://example.com/photo4.jpg", Width: 640, Height: 480, Quality: 80}, {ImageID: "img005", SourceURL: "https://example.com/photo5.jpg", Width: 5000, Height: 3000, Quality: 90}, // This will fail {ImageID: "img006", SourceURL: "https://example.com/photo6.jpg", Width: 2560, Height: 1440, Quality: 85}, {ImageID: "img007", SourceURL: "https://example.com/photo7.jpg", Width: 3840, Height: 2160, Quality: 90}, {ImageID: "img008", SourceURL: "https://example.com/photo8.jpg", Width: 1024, Height: 768, Quality: 85}, } fmt.Printf("\nSubmitting %d images for processing...\n\n", len(images)) for _, img := range images { processor.Submit(img) } // Shutdown processor (waits for all jobs to complete) processor.Shutdown() // Wait for result collector to finish resultWg.Wait() }
Expected Output:
Image processor started with 3 workers Submitting 8 images for processing... SUCCESS: Image img001 processed in 220ms (2441.4 KB -> 140.6 KB) SUCCESS: Image img002 processed in 220ms (2441.4 KB -> 281.3 KB) SUCCESS: Image img003 processed in 220ms (2441.4 KB -> 607.5 KB) SUCCESS: Image img004 processed in 220ms (2441.4 KB -> 90.0 KB) FAILED: Image img005 - image too large: max width is 4000px SUCCESS: Image img006 processed in 220ms (2441.4 KB -> 1080.0 KB) SUCCESS: Image img007 processed in 220ms (2441.4 KB -> 2430.0 KB) SUCCESS: Image img008 processed in 220ms (2441.4 KB -> 230.4 KB) Worker 1: job channel closed Worker 2: job channel closed Worker 3: job channel closed Initiating graceful shutdown... Shutdown complete Processing complete: 7 succeeded, 1 failed
Real World Example 2: Database Batch Processor
Processing large amounts of database records efficiently:
go// Filename: database_batch_processor.go package main import ( "context" "fmt" "math/rand" "sync" "sync/atomic" "time" ) // User represents a database user record type User struct { ID int Email string Name string LastLogin time.Time } // EmailJob represents an email to be sent type EmailJob struct { UserID int Email string Name string Subject string Body string } // EmailResult represents the result of sending an email type EmailResult struct { UserID int Success bool Error error Duration time.Duration } // BatchEmailSender processes emails in batches with controlled concurrency type BatchEmailSender struct { numWorkers int jobs chan EmailJob results chan EmailResult wg sync.WaitGroup totalSent int64 totalFailed int64 totalProcessed int64 } // NewBatchEmailSender creates a new batch email sender func NewBatchEmailSender(numWorkers int) *BatchEmailSender { return &BatchEmailSender{ numWorkers: numWorkers, jobs: make(chan EmailJob, numWorkers*10), // Buffer 10x workers results: make(chan EmailResult, numWorkers*10), } } // Start begins the worker pool func (s *BatchEmailSender) Start(ctx context.Context) { for i := 1; i <= s.numWorkers; i++ { s.wg.Add(1) go s.emailWorker(ctx, i) } fmt.Printf("Email sender started with %d workers\n", s.numWorkers) } // emailWorker sends emails from the job queue func (s *BatchEmailSender) emailWorker(ctx context.Context, id int) { defer s.wg.Done() for { select { case <-ctx.Done(): return case job, ok := <-s.jobs: if !ok { return } result := s.sendEmail(job) s.results <- result // Update counters atomically atomic.AddInt64(&s.totalProcessed, 1) if result.Success { atomic.AddInt64(&s.totalSent, 1) } else { atomic.AddInt64(&s.totalFailed, 1) } } } } // sendEmail simulates sending an email func (s *BatchEmailSender) sendEmail(job EmailJob) EmailResult { start := time.Now() // Simulate email sending with variable latency delay := time.Duration(20+rand.Intn(80)) * time.Millisecond time.Sleep(delay) // Simulate 5% failure rate var err error success := true if rand.Float32() < 0.05 { err = fmt.Errorf("SMTP connection failed") success = false } return EmailResult{ UserID: job.UserID, Success: success, Error: err, Duration: time.Since(start), } } // Submit adds an email job to the queue func (s *BatchEmailSender) Submit(job EmailJob) { s.jobs <- job } // Results returns the results channel func (s *BatchEmailSender) Results() <-chan EmailResult { return s.results } // Stats returns current processing statistics func (s *BatchEmailSender) Stats() (processed, sent, failed int64) { return atomic.LoadInt64(&s.totalProcessed), atomic.LoadInt64(&s.totalSent), atomic.LoadInt64(&s.totalFailed) } // Shutdown gracefully stops the sender func (s *BatchEmailSender) Shutdown() { close(s.jobs) s.wg.Wait() close(s.results) } // simulateGetInactiveUsers simulates fetching inactive users from database func simulateGetInactiveUsers(count int) []User { users := make([]User, count) for i := 0; i < count; i++ { users[i] = User{ ID: i + 1, Email: fmt.Sprintf("user%d@example.com", i+1), Name: fmt.Sprintf("User %d", i+1), LastLogin: time.Now().AddDate(0, 0, -30-rand.Intn(60)), } } return users } func main() { rand.Seed(time.Now().UnixNano()) // Create sender with 10 workers (simulating 10 concurrent SMTP connections) sender := NewBatchEmailSender(10) ctx, cancel := context.WithCancel(context.Background()) defer cancel() sender.Start(ctx) // Start progress reporter go func() { ticker := time.NewTicker(500 * time.Millisecond) defer ticker.Stop() for { select { case <-ctx.Done(): return case <-ticker.C: processed, sent, failed := sender.Stats() fmt.Printf("Progress: %d processed, %d sent, %d failed\n", processed, sent, failed) } } }() // Start result collector var resultWg sync.WaitGroup resultWg.Add(1) go func() { defer resultWg.Done() for result := range sender.Results() { if !result.Success { fmt.Printf(" Failed to send to user %d: %v\n", result.UserID, result.Error) } } }() // Get inactive users (simulating database query) fmt.Println("Fetching inactive users...") users := simulateGetInactiveUsers(100) fmt.Printf("Found %d inactive users\n\n", len(users)) // Submit email jobs fmt.Println("Submitting email jobs...") startTime := time.Now() for _, user := range users { sender.Submit(EmailJob{ UserID: user.ID, Email: user.Email, Name: user.Name, Subject: "We miss you!", Body: fmt.Sprintf("Hi %s, it's been a while since we saw you...", user.Name), }) } // Shutdown and wait sender.Shutdown() cancel() // Stop progress reporter resultWg.Wait() // Final stats totalDuration := time.Since(startTime) processed, sent, failed := sender.Stats() fmt.Printf("\n" + "=" + "\n") fmt.Printf("Final Results:\n") fmt.Printf(" Total processed: %d\n", processed) fmt.Printf(" Successfully sent: %d\n", sent) fmt.Printf(" Failed: %d\n", failed) fmt.Printf(" Total time: %v\n", totalDuration) fmt.Printf(" Throughput: %.1f emails/second\n", float64(processed)/totalDuration.Seconds()) }
Expected Output:
Email sender started with 10 workers Fetching inactive users... Found 100 inactive users Submitting email jobs... Progress: 45 processed, 43 sent, 2 failed Failed to send to user 12: SMTP connection failed Failed to send to user 34: SMTP connection failed Progress: 89 processed, 85 sent, 4 failed Failed to send to user 67: SMTP connection failed Failed to send to user 78: SMTP connection failed Progress: 100 processed, 95 sent, 5 failed Failed to send to user 91: SMTP connection failed = Final Results: Total processed: 100 Successfully sent: 95 Failed: 5 Total time: 1.12s Throughput: 89.3 emails/second
Advanced Worker Pool Features
Dynamic Worker Pool with Auto-Scaling
go// Filename: dynamic_worker_pool.go package main import ( "context" "fmt" "sync" "sync/atomic" "time" ) // DynamicPool automatically scales workers based on queue depth type DynamicPool struct { minWorkers int maxWorkers int jobs chan func() workerCount int64 wg sync.WaitGroup ctx context.Context cancel context.CancelFunc mu sync.Mutex } // NewDynamicPool creates a pool that scales between min and max workers func NewDynamicPool(minWorkers, maxWorkers int) *DynamicPool { ctx, cancel := context.WithCancel(context.Background()) pool := &DynamicPool{ minWorkers: minWorkers, maxWorkers: maxWorkers, jobs: make(chan func(), maxWorkers*100), ctx: ctx, cancel: cancel, } // Start minimum workers for i := 0; i < minWorkers; i++ { pool.addWorker() } // Start the scaler go pool.scaler() return pool } // addWorker adds a new worker to the pool func (p *DynamicPool) addWorker() { p.wg.Add(1) atomic.AddInt64(&p.workerCount, 1) go func() { defer p.wg.Done() defer atomic.AddInt64(&p.workerCount, -1) idleTimeout := time.NewTimer(30 * time.Second) defer idleTimeout.Stop() for { idleTimeout.Reset(30 * time.Second) select { case <-p.ctx.Done(): return case job, ok := <-p.jobs: if !ok { return } job() case <-idleTimeout.C: // Idle timeout - consider shutting down if we're above minimum if atomic.LoadInt64(&p.workerCount) > int64(p.minWorkers) { fmt.Println("Worker idle timeout, shutting down") return } } } }() } // scaler monitors queue depth and scales workers accordingly func (p *DynamicPool) scaler() { ticker := time.NewTicker(100 * time.Millisecond) defer ticker.Stop() for { select { case <-p.ctx.Done(): return case <-ticker.C: queueDepth := len(p.jobs) currentWorkers := atomic.LoadInt64(&p.workerCount) // Scale up if queue is getting deep if queueDepth > int(currentWorkers)*5 && currentWorkers < int64(p.maxWorkers) { fmt.Printf("Scaling up: queue=%d, workers=%d\n", queueDepth, currentWorkers) p.addWorker() } } } } // Submit adds a job to the pool func (p *DynamicPool) Submit(job func()) { p.jobs <- job } // WorkerCount returns current number of active workers func (p *DynamicPool) WorkerCount() int64 { return atomic.LoadInt64(&p.workerCount) } // QueueDepth returns current number of jobs waiting func (p *DynamicPool) QueueDepth() int { return len(p.jobs) } // Shutdown gracefully stops the pool func (p *DynamicPool) Shutdown() { close(p.jobs) p.cancel() p.wg.Wait() } func main() { pool := NewDynamicPool(2, 10) fmt.Printf("Starting with %d workers\n", pool.WorkerCount()) // Submit burst of jobs var jobWg sync.WaitGroup for i := 0; i < 100; i++ { jobWg.Add(1) jobNum := i pool.Submit(func() { defer jobWg.Done() time.Sleep(100 * time.Millisecond) // Simulate work fmt.Printf("Job %d completed (workers: %d, queue: %d)\n", jobNum, pool.WorkerCount(), pool.QueueDepth()) }) } // Wait for jobs to complete jobWg.Wait() fmt.Printf("\nAll jobs done. Workers: %d\n", pool.WorkerCount()) // Wait a bit to see workers scale down fmt.Println("Waiting for idle workers to scale down...") time.Sleep(35 * time.Second) fmt.Printf("After idle period. Workers: %d\n", pool.WorkerCount()) pool.Shutdown() }
Worker Pool with Retries and Dead Letter Queue
go// Filename: worker_pool_with_retry.go package main import ( "errors" "fmt" "math/rand" "sync" "time" ) // RetryableJob is a job that can be retried on failure type RetryableJob struct { ID int Data string Attempts int MaxAttempts int LastError error } // DeadLetterEntry is a job that exceeded retry attempts type DeadLetterEntry struct { Job RetryableJob FinalError error FailedAt time.Time } // RetryableWorkerPool handles jobs with automatic retry type RetryableWorkerPool struct { numWorkers int jobs chan RetryableJob retryQueue chan RetryableJob deadLetterQueue chan DeadLetterEntry wg sync.WaitGroup } // NewRetryableWorkerPool creates a pool with retry support func NewRetryableWorkerPool(numWorkers int) *RetryableWorkerPool { return &RetryableWorkerPool{ numWorkers: numWorkers, jobs: make(chan RetryableJob, 100), retryQueue: make(chan RetryableJob, 100), deadLetterQueue: make(chan DeadLetterEntry, 100), } } // Start begins the worker pool func (p *RetryableWorkerPool) Start() { // Start main workers for i := 1; i <= p.numWorkers; i++ { p.wg.Add(1) go p.worker(i) } // Start retry processor p.wg.Add(1) go p.retryProcessor() } // worker processes jobs func (p *RetryableWorkerPool) worker(id int) { defer p.wg.Done() for job := range p.jobs { job.Attempts++ err := p.processJob(job) if err != nil { job.LastError = err if job.Attempts >= job.MaxAttempts { // Send to dead letter queue p.deadLetterQueue <- DeadLetterEntry{ Job: job, FinalError: err, FailedAt: time.Now(), } fmt.Printf("Worker %d: Job %d moved to DLQ after %d attempts: %v\n", id, job.ID, job.Attempts, err) } else { // Send for retry p.retryQueue <- job fmt.Printf("Worker %d: Job %d failed (attempt %d/%d), queued for retry: %v\n", id, job.ID, job.Attempts, job.MaxAttempts, err) } } else { fmt.Printf("Worker %d: Job %d succeeded on attempt %d\n", id, job.ID, job.Attempts) } } } // processJob simulates job processing with random failures func (p *RetryableWorkerPool) processJob(job RetryableJob) error { time.Sleep(50 * time.Millisecond) // 40% chance of failure if rand.Float32() < 0.4 { return errors.New("random processing error") } return nil } // retryProcessor handles retry with exponential backoff func (p *RetryableWorkerPool) retryProcessor() { defer p.wg.Done() for job := range p.retryQueue { // Exponential backoff: 100ms, 200ms, 400ms, etc. backoff := time.Duration(100<<uint(job.Attempts-1)) * time.Millisecond if backoff > 5*time.Second { backoff = 5 * time.Second } fmt.Printf("Retry processor: Job %d waiting %v before retry\n", job.ID, backoff) time.Sleep(backoff) // Resubmit to main queue p.jobs <- job } } // Submit adds a job to the pool func (p *RetryableWorkerPool) Submit(job RetryableJob) { p.jobs <- job } // DeadLetterQueue returns the DLQ channel for monitoring func (p *RetryableWorkerPool) DeadLetterQueue() <-chan DeadLetterEntry { return p.deadLetterQueue } // Shutdown gracefully stops the pool func (p *RetryableWorkerPool) Shutdown() { close(p.jobs) close(p.retryQueue) p.wg.Wait() close(p.deadLetterQueue) } func main() { rand.Seed(time.Now().UnixNano()) pool := NewRetryableWorkerPool(3) pool.Start() // Monitor dead letter queue var dlqWg sync.WaitGroup dlqWg.Add(1) go func() { defer dlqWg.Done() for entry := range pool.DeadLetterQueue() { fmt.Printf("\n*** DLQ ALERT: Job %d permanently failed: %v ***\n\n", entry.Job.ID, entry.FinalError) } }() // Submit jobs for i := 1; i <= 10; i++ { pool.Submit(RetryableJob{ ID: i, Data: fmt.Sprintf("task-%d", i), MaxAttempts: 3, }) } // Wait a bit for processing time.Sleep(5 * time.Second) pool.Shutdown() dlqWg.Wait() fmt.Println("\nPool shutdown complete") }
Best Practices and Common Mistakes
Best Practices
go// Filename: worker_pool_best_practices.go package main import ( "context" "fmt" "runtime" "sync" "time" ) // BEST PRACTICE 1: Size your worker pool appropriately func recommendedWorkerCount(workType string) int { numCPU := runtime.NumCPU() switch workType { case "cpu-bound": // CPU-bound work: match CPU cores return numCPU case "io-bound": // IO-bound work: can have more workers than CPUs // because they spend most time waiting return numCPU * 4 case "mixed": // Mixed workload: somewhere in between return numCPU * 2 case "external-limited": // Limited by external resource (e.g., database connections) // Match the external limit return 25 // Example: typical DB connection pool size default: return numCPU } } // BEST PRACTICE 2: Always use context for cancellation func workerWithContext(ctx context.Context, id int, jobs <-chan int) { for { select { case <-ctx.Done(): fmt.Printf("Worker %d: cancelled\n", id) return case job, ok := <-jobs: if !ok { return } fmt.Printf("Worker %d: processing job %d\n", id, job) } } } // BEST PRACTICE 3: Use buffered channels appropriately func createChannels(numWorkers int) (chan int, chan int) { // Job channel: buffer based on expected burst size // Too small: producer blocks frequently // Too large: wastes memory jobs := make(chan int, numWorkers*10) // Result channel: buffer based on processing needs results := make(chan int, numWorkers*10) return jobs, results } // BEST PRACTICE 4: Graceful shutdown pattern type GracefulPool struct { jobs chan int wg sync.WaitGroup ctx context.Context cancel context.CancelFunc } func NewGracefulPool(workers int) *GracefulPool { ctx, cancel := context.WithCancel(context.Background()) p := &GracefulPool{ jobs: make(chan int, workers*10), ctx: ctx, cancel: cancel, } for i := 0; i < workers; i++ { p.wg.Add(1) go p.worker(i) } return p } func (p *GracefulPool) worker(id int) { defer p.wg.Done() for { select { case <-p.ctx.Done(): // Drain remaining jobs before exiting for job := range p.jobs { fmt.Printf("Worker %d: processing remaining job %d\n", id, job) } return case job, ok := <-p.jobs: if !ok { return } fmt.Printf("Worker %d: processing job %d\n", id, job) time.Sleep(10 * time.Millisecond) } } } func (p *GracefulPool) Submit(job int) { p.jobs <- job } func (p *GracefulPool) Shutdown(timeout time.Duration) error { close(p.jobs) // Stop accepting new jobs done := make(chan struct{}) go func() { p.wg.Wait() close(done) }() select { case <-done: return nil case <-time.After(timeout): p.cancel() // Force cancel if timeout return fmt.Errorf("shutdown timed out") } } func main() { fmt.Println("Recommended worker counts:") fmt.Printf(" CPU-bound: %d\n", recommendedWorkerCount("cpu-bound")) fmt.Printf(" IO-bound: %d\n", recommendedWorkerCount("io-bound")) fmt.Printf(" Mixed: %d\n", recommendedWorkerCount("mixed")) fmt.Printf(" External-limited: %d\n", recommendedWorkerCount("external-limited")) fmt.Println("\nDemonstrating graceful shutdown:") pool := NewGracefulPool(3) // Submit some jobs for i := 1; i <= 20; i++ { pool.Submit(i) } // Graceful shutdown with 5 second timeout if err := pool.Shutdown(5 * time.Second); err != nil { fmt.Printf("Shutdown error: %v\n", err) } else { fmt.Println("Shutdown completed gracefully") } }
Common Mistakes to Avoid
go// Filename: worker_pool_mistakes.go package main import ( "fmt" "sync" "time" ) // MISTAKE 1: Forgetting to close channels func mistakeUnclosedChannel() { jobs := make(chan int, 10) var wg sync.WaitGroup // Worker wg.Add(1) go func() { defer wg.Done() for job := range jobs { fmt.Println("Processing:", job) } // This will never be reached if jobs is never closed! }() for i := 0; i < 5; i++ { jobs <- i } // MISTAKE: Forgetting to close(jobs) // The worker goroutine will hang forever! // close(jobs) // <- This line is missing // wg.Wait() // This would deadlock } // CORRECT: Always close channels when done sending func correctCloseChannel() { jobs := make(chan int, 10) var wg sync.WaitGroup wg.Add(1) go func() { defer wg.Done() for job := range jobs { fmt.Println("Processing:", job) } }() for i := 0; i < 5; i++ { jobs <- i } close(jobs) // Signal no more jobs wg.Wait() // Now this works correctly } // MISTAKE 2: Sending to closed channel (causes panic) func mistakeSendToClosedChannel() { defer func() { if r := recover(); r != nil { fmt.Println("Recovered from panic:", r) } }() jobs := make(chan int) close(jobs) jobs <- 1 // PANIC: send on closed channel } // MISTAKE 3: Not using WaitGroup correctly func mistakeWaitGroup() { var wg sync.WaitGroup for i := 0; i < 5; i++ { // MISTAKE: wg.Add inside goroutine can cause race go func(n int) { wg.Add(1) // Wrong place! defer wg.Done() fmt.Println(n) }(i) } wg.Wait() // May finish before goroutines even start! } // CORRECT: Add before starting goroutine func correctWaitGroup() { var wg sync.WaitGroup for i := 0; i < 5; i++ { wg.Add(1) // Add before goroutine starts go func(n int) { defer wg.Done() fmt.Println(n) }(i) } wg.Wait() } // MISTAKE 4: Not buffering result channel appropriately func mistakeUnbufferedResults() { jobs := make(chan int, 100) results := make(chan int) // Unbuffered! // Workers for w := 0; w < 3; w++ { go func() { for job := range jobs { // If main isn't reading results fast enough, // this send will block, reducing throughput results <- job * 2 } }() } // Send jobs for i := 0; i < 10; i++ { jobs <- i } close(jobs) // If we don't read results, workers will block forever! } // CORRECT: Buffer based on expected throughput func correctBufferedResults() { jobs := make(chan int, 100) results := make(chan int, 100) // Buffered appropriately var wg sync.WaitGroup // Workers for w := 0; w < 3; w++ { wg.Add(1) go func() { defer wg.Done() for job := range jobs { results <- job * 2 } }() } // Send jobs for i := 0; i < 10; i++ { jobs <- i } close(jobs) // Wait and close results go func() { wg.Wait() close(results) }() // Collect results for result := range results { fmt.Println("Result:", result) } } func main() { fmt.Println("Demonstrating correct patterns:") correctCloseChannel() fmt.Println() correctWaitGroup() fmt.Println() correctBufferedResults() }
When to Use Worker Pool Pattern
Use Worker Pool When:
| Scenario | Why Worker Pool Helps |
|---|---|
| Database operations | Limited connection pool |
| API calls | Rate limits, connection limits |
| File processing | Disk I/O bottleneck |
| Image/video processing | Memory constraints |
| Email sending | SMTP connection limits |
| Web scraping | Politeness, rate limiting |
| Batch processing | Resource efficiency |
Don't Use Worker Pool When:
| Scenario | Better Alternative |
|---|---|
| Few, quick tasks | Simple goroutines |
| Single long-running task | Single goroutine |
| Unlimited resources | May not need pooling |
| Real-time streaming | Pipeline pattern |
| Task dependencies | DAG/workflow patterns |
Summary
The Worker Pool pattern is your go-to solution when you need controlled concurrency. Like a well-run kitchen with a fixed number of chefs, it provides:
- Resource Control: Fixed number of concurrent operations
- Backpressure: Queue depth provides natural rate limiting
- Efficiency: Reuse goroutines instead of creating new ones
- Predictability: Known resource usage under load
Key Takeaways:
- Size pools based on bottleneck: CPU cores for CPU-bound, more for I/O-bound
- Buffer channels appropriately: Too small blocks producers, too large wastes memory
- Always close channels: When producer is done, close the jobs channel
- Use context for cancellation: Allows graceful shutdown
- Consider retries: Production systems need failure handling
- Monitor queue depth: Helps identify bottlenecks
Next Steps
- Practice: Implement a worker pool for your next batch processing task
- Explore: Fan-Out/Fan-In pattern for parallel processing with aggregation
- Read: Go's context package for deadline and cancellation propagation
- Build: Add metrics (prometheus) to monitor your worker pools in production